MARKET BASKET ANALYSIS
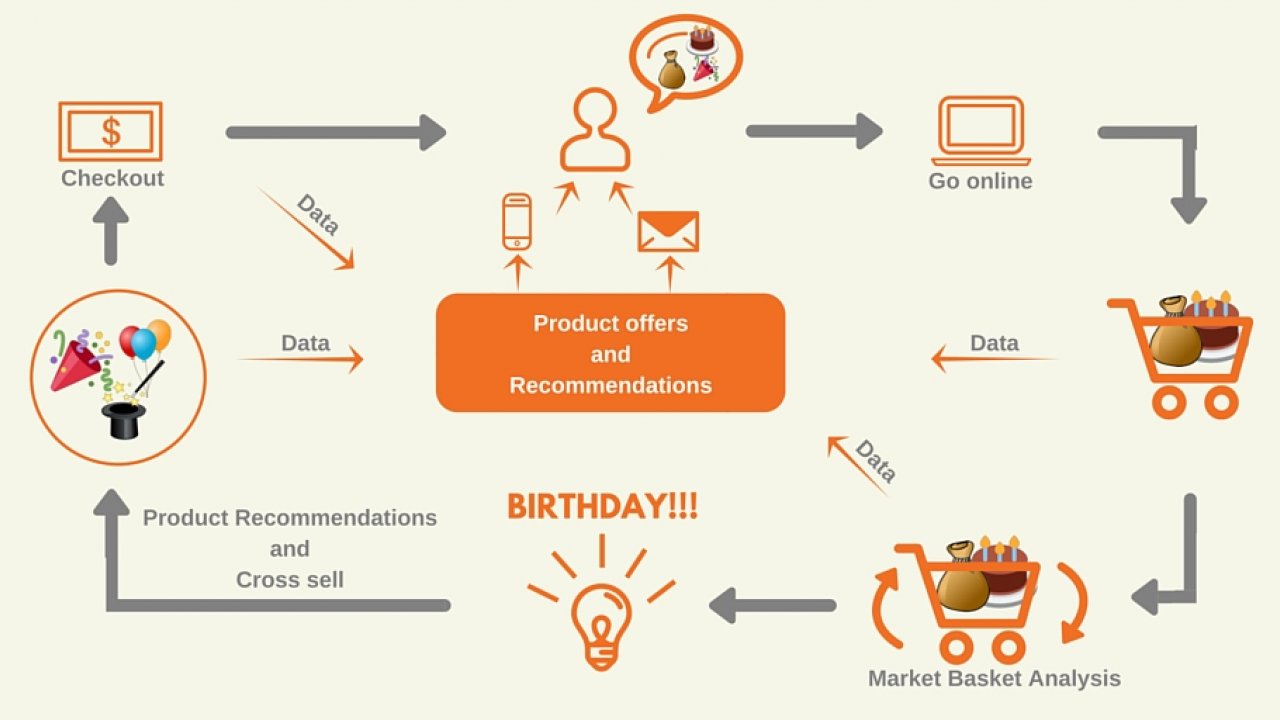
Market basket analysis (MBA) is a modelling technique, traditionally used by retailers, to understand customer behaviour. It is derived from affinity analysis and association rule learning which implies connections between specific objects by examining the significance of the co – occurrence of the objects among specific individuals or groups. In the context of a supermarket or a retail store, market basket analysis would try to find the combination of products that frequently co – occur in transactions, e.g. people who buy bread and eggs, also tend to buy butter (as a high proportion of them are planning on making an omelette).1
Brick and mortar stores use the insights gained from MBA to drive their sales by creating store layouts where commonly co-occurring products are placed near each other to improve the customer shopping experience. It is also used to cross sell different products, e.g., customers who buy flour are targeted with offers on eggs, to encourage them to spend more on their shopping basket.
A few other examples on how MBA is used are2
- Product recommendation by online retailers, e.g. Amazon’s customers who bought this product also bought these products…
- Placement of content items on web pages
- Optional services purchased by telecommunications customers (call waiting, call forwarding, DSL, speed call, and so on) help determine how to bundle these services together to maximize revenue
- Unusual combinations of insurance claims are indicative of fraud
- Medical patient histories can give indications of likely complications based on certain combinations of treatments.
Terminology 3
Items are the objects that we are identifying associations between. For a retailer, an item will be a product in the shop. For a publisher, an item might be an article, a blog post, a video etc. In association analysis, a collection of zero or more items is called an itemset.
Transactions are instances of groups of items co-occurring together. In a store, a transaction would generally be summarized in the receipt. The receipt would be a list of all the items bought by a single customer.
Market basket data can be represented in binary form where each row represents a transaction and each column represents an item. An item being purchased is treated like a binary variable and is given the value of 1 for purchase in a transaction and 0 otherwise. The binary representation, however, does not account for the quantity of item in the transactions, only its presence/ absence.

Rules provide information in the form of if – then statements.
X ⇒Y
i.e. if a customer chooses the items on the left-hand side of the rule (antecedent i.e. X), then it is likely that the customer will be interested in the item on the right-hand side (consequent i.e. Y). The antecedent and consequent are disjoint and should have no items in common. Thus, in the example of bread and eggs, the rule would be:
{bread, eggs} ⇒{butter}
The output of a market basket analysis is generally a set of rules, which are then used to make business decisions.
The support of an item or itemset is the proportion of transactions in the data set that contain that item or itemset. Thus, it indicates the popularity of the item. For super market retailers, this is likely to involve basic products that are popular across an entire user base (e.g. bread, milk). On the other hand, a printer cartridge retailer may not have products with a high support, because each customer only buys cartridges that are specific to his / her own printer.
Confidence of a rule is the conditional probability that a randomly selected transaction will contain items on the consequent of the rule, given the presence of items on the antecedent of the rule.
It is merely the likelihood of the consequent being purchased as a result of purchasing the antecedent. Rules with higher confidence are ones where the probability of an item appearing on the consequent is high given the presence of the items on the antecedent.
The lift of a rule is the probability of co-occurrence of the items on the antecedent and consequent divided by the expected probability of the occurrence of the items on the antecedent and consequent if the two were independent.

- Lift > 1 suggests that the presence of the items on the antecedent has increased the probability that the items on the consequent will occur on this transaction.
- Lift < 1 suggests that the presence of the items on the antecedent has decreased the probability that the items on the consequent will occur in the transaction.
- Lift = 1 suggests that the presence of items on the antecedent and consequent are independent i.e. presence of items on the antecedent are present does not affect the probability that items on the consequent will occur.
Rules with a lift of more than one are generally preferred while performing a market basket analysis.
Example: A sample of 15 transactions from a grocery store shows purchases of five items: bread, apples, jam, flour and ketchup. The grocer wishes to know the popularity of bread and jam. He also wants to know if the sale of jam is dependent on bread.

Thus, bread and jam prove to be most popular as shown by high support values. Lift of 1.1 also suggests that the sale of jam has been influenced by the sale of bread.
Typically, a decision maker would be more interested in a complete list of popular itemsets than know the popularity of a select few. To create the list, one needs to calculate the support values for all possible configuration of items and shortlist frequent itemsets that meet the minimum support threshold to arrive at meaningful associations using confidence/lift values. Thus, the entire process can be divided into two steps:
- Frequent itemset generation
- Rule generation
Frequent itemset generation can become computationally expensive as the number of possible configurations for k items is 2k – 1. Thus, for 5 items, the number of itemsets would be 31; for 10 items, it would be 1023 and so on. This necessitates an approach to reduce the number of configurations which need to be considered.

Apriori algorithm 4 is the most widely used algorithm to efficiently generate association rules. It is based on the Apriori principle.
Apriori principle:
- If an itemset is frequent, then all its subsets must also be frequent
- if an itemset is infrequent, then all its supersets must also be infrequent
The Apriori principle holds due to the anti-monotone property of support which states that the support of an itemset never exceeds the support of its subsets.
Apriori algorithm uses a “bottom up” approach to generate frequent itemsets:
Step 1. Let k=1. All possible itemsets of length k are generated. These are known as candidate itemsets.
Step 2. The itemsets whose support is equal to or more than the minimum support threshold are selected as the frequent itemsets.
Step 3. The following steps are repeated until no new frequent itemsets are found.
- Candidates itemsets of length k+1 are generated from frequent itemsets of length k.
- Candidate itemsets containing subsets of length k that are infrequent are removed (Pruning)
- >Support of each candidate itemset of length k+1 is calculated.
- Candidates that are found infrequent based on their support are eliminated, leaving only frequent itemsets.

5Example: A sample of five transactions are taken. A minimum threshold support of 40% is chosen.


Apriori principle is again used to identify item associations with high confidence or lift to generate rules. Finding rules with high confidence or lift is less computationally taxing once high-support itemsets have been identified, as confidence and lift values are calculated using support values of the remaining frequent itemsets.
Since, distribution of items differs across businesses, it is expected that support and confidence parameters will change according to the organization. Thus, it is required for organisations to experiment with different parameters. However, rules generated from low parameters should be treated with caution as they can indicate spurious associations.
0 Comments.